Data Science¶
Description |
Tools for statistical analysis and machine learning. |
|---|---|
Projects |
85 |
Size vs. Trend Chart (click to view) |
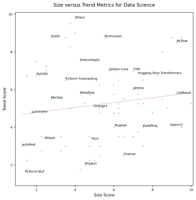
|
Sub-categories¶
Category |
Description |
Projects |
|---|---|---|
Anomaly detection (also called outlier detection) is about finding data points that do not fit into the overall pattern of a data set. Applications include failure detection, fraud detection, security, and data cleansing. Algorithms may work on arbitrary datasets or be specific to a data type, such as time series or graph data. In general, algorithms may look for individual outlier points, a pattern involving multiple points, or compare entire data sets. A related problem is change point detection, where one is looking for changes in the pattern of time series data. |
4 |
|
This is a general term used by applications which try to reduce the data scientist’s workload when creating a machine learning model. Auto ML tools typically perform data cleansing operations and then try out various ML algorithms to see which perform the best. |
4 |
|
Computer Vision is about processing and understanding of image and video data. Machine learning can be used in computer vision to support many applications, including image classification, object detection, facial recognition, motion tracking, and image enhancement. |
5 |
|
Libraries that provide data manipulation and mathematical primitives. Many of these libraries are key components used by other data science projects. |
11 |
|
Deep Learning frameworks provide support for training and inference of deep neural networks (more than 3 layers). Deep Learning is compute intensive, and most Deep Learning focused frameworks support GPU acceleration. |
17 |
|
In the world of software engineering, an Integrated Development Environment (IDE) provides a graphical interface to edit, compile, run, and debug code. When developing software in Java or .NET, or for mobile applications, IDEs are widely used. The idea of an Integrated Development Environment for machine learning is less well developed and not widely used. For the tools that exist, they are frequently paired with Auto ML capabilities. |
3 |
|
Training of machine learning models across multiple servers and/or GPUs. |
3 |
|
These projects typically track the history of machine learning experiments, capturing input parameters and results. They may also track the steps in a data pipeline and how a final data set was derived from source data. |
5 |
|
Deep Learning models tend to be “black box” and do not provide much feedback on which features determined a given output (class label or regression value). Projects in Explainable AI use various approaches to provide insight into the factors behind a model’s decision. |
4 |
|
Feature engineering focuses on how to extract, select, and contruct features from raw data. Feature engineering method is depending on the dataset types. Different datasets require different approaches. |
4 |
|
The libraries in this application area provide general-purpose machine learning functionality including preprocessing, clustering, regression, support vector classifier, K-nearest neighbors, decision trees, etc. Note that some general machine learning algorithms might not benefit from GPU acceleration as much as Deep Learning. |
5 |
|
Gradient boosting is an approach to machine learning which takes a simple, weak model and iteratively adds to it, reducing the error. This has proven to be very effective with decision trees, often with results rivaling deep learning, but with less need for tuning. Most projects provide Scikit-learn compatible APIs. If you wish to try out various classification (or regression) algorithms, you can compare against the various algorithms provided by scikit-learn without changing your code. |
3 |
|
“ML Operations” is the combination of “DevOps” and Machine Learning. Tools in the MLOps space provide the infrastructure to put machine learning models in production. These tools may include training and testing of models, a generic pipeline/workflow mechanism, model registries, scalable model serving via HTTP, and metrics capture. |
5 |
|
This category is for projects whose primary purpose is to integrate other machine learning projects. |
1 |
|
Natural Language Processing (NLP) projects provide tools for parsing and understanding text data. These tools range from parsing and stemming words to state-of-the-art neural network models. |
7 |
|
Nearest Neighbors is a simple yet effective machine learning algorithm that looks at the closest datapoints in a multidimensional space. Nearest Neighbors algorithms are implemented on top of a vector similarity algorithm, which compares vectors and computes a similarity score for ranking purposes. Approximate Nearest Neighbors approximates this algorithm for very large data sets. |
2 |
|
These projects provide functionality to calculate probability distributions over functions and combinations of variables, sampling, and other functionality related to Bayesian Modeling. |
2 |
|
These projects provide functionality to process time series data. This includes feature extraction, prediction, trend analysis, and machine learning. |
12 |