Apache¶
Website |
|
|---|---|
Description |
Apache is the world’s largest open source foundation with over 300 top-level projects. |
Size vs. Trend Chart (click to view) |
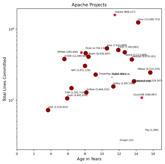
|
Projects¶
Project |
Size Score |
Trend Score |
Byline |
|---|---|---|---|
3.75 |
7.0 |
Graph database optimized for fast analysis and real-time data processing. It is provided as an extension to PostgreSQL. |
|
8.25 |
8.5 |
Apache Airflow - A platform to programmatically author, schedule, and monitor workflows |
|
9.0 |
8.25 |
Apache Beam is a unified model for defining both batch and streaming data-parallel processing pipelines, as well as a set of language-specific SDKs for constructing pipelines and Runners for executing them on distributed processing backends, including Apache Flink, Apache Spark, Google Cloud Dataflow and Hazelcast Jet. |
|
8.25 |
5.75 |
The Apache Cassandra database is the right choice when you need scalability and high availability without compromising performance. |
|
6.25 |
5.25 |
CouchDB is an open source NoSQL database. |
|
9.25 |
7.0 |
Apache Flink is an open source stream processing framework with powerful stream- and batch-processing capabilities. |
|
3.5 |
3.0 |
Apache Giraph is an iterative graph processing system built for high scalability. |
|
8.25 |
5.0 |
Apache HBase is an open-source, distributed, versioned, column-oriented store. |
|
9.0 |
8.25 |
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. |
|
9.25 |
4.75 |
The Apache Hive data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL. Structure can be projected onto data already in storage. A command line tool and JDBC driver are provided to connect users to Hive. |
|
6.75 |
8.0 |
Hudi is a rich platform to build streaming data lakes with incremental data pipelines on a self-managing database layer, while being optimized for lake engines and regular batch processing. |
|
7.25 |
4.5 |
Apache Impala is the open source, native analytic database for Apache Hadoop. Impala provides low latency and high concurrency for BI/analytic queries on Hadoop (not delivered by batch frameworks such as Apache Hive). |
|
7.75 |
8.75 |
IoTDB (Internet of Things Database) is a data management system for time series data, which can provide users specific services, such as, data collection, storage and analysis. |
|
7.75 |
5.0 |
A free and open source Java framework for building Semantic Web and Linked Data applications. |
|
8.5 |
5.0 |
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications. |
|
6.5 |
3.5 |
A flexible and efficient library for deep learning. |
|
4.75 |
2.25 |
Apache Mahout is a distributed linear algebra framework and mathematically expressive Scala DSL designed to let mathematicians, statisticians, and data scientists quickly implement their own algorithms. |
|
8.5 |
5.0 |
Apache NiFi supports highly configurable directed graphs of data routing, transformation, and system mediation logic. |
|
4.0 |
5.0 |
Apache Pig is a platform to create programs on top of Apache Hadoop. |
|
6.5 |
7.0 |
Apache Pinot (Incubating) - A realtime distributed OLAP datastore |
|
9.25 |
4.5 |
A unified analytics engine for large-scale data processing. |
|
6.5 |
3.0 |
Storm is a distributed realtime computation system. |
|
7.0 |
7.0 |
Open deep learning compiler stack for cpu, gpu and specialized accelerators |
|
7.5 |
5.25 |
Apache TinkerPop™ is a graph computing framework for both graph databases (OLTP) and graph analytic systems (OLAP). |