Hudi¶
Hudi is an ingestion tool and data file organization to add fast ingestion support to the Hadoop platform. Data ingested via Hudi can be queried by Hive, Spark, and Presto. The name Hudi stands for “Hadoop Update, Delete, Insert”.
Logo |

|
|---|---|
Website |
|
Repository |
|
Byline |
Hudi is a rich platform to build streaming data lakes with incremental data pipelines on a self-managing database layer, while being optimized for lake engines and regular batch processing. |
License |
Apache 2.0 |
Project age |
5 years 11 months |
Backers |
Apache (Governed by), Uber (Creator) |
Lastest News (2022-08-17) |
0.12.0 Many changes in Hudi 0.12, including Presto connector and support for archive beyond savepoints. See the Release Highlights for … more |
Size score (1 to 10, higher is better) |
6.75 |
Trend score (1 to 10, higher is better) |
8.0 |
Education Resources¶
No recent documentation available for project.
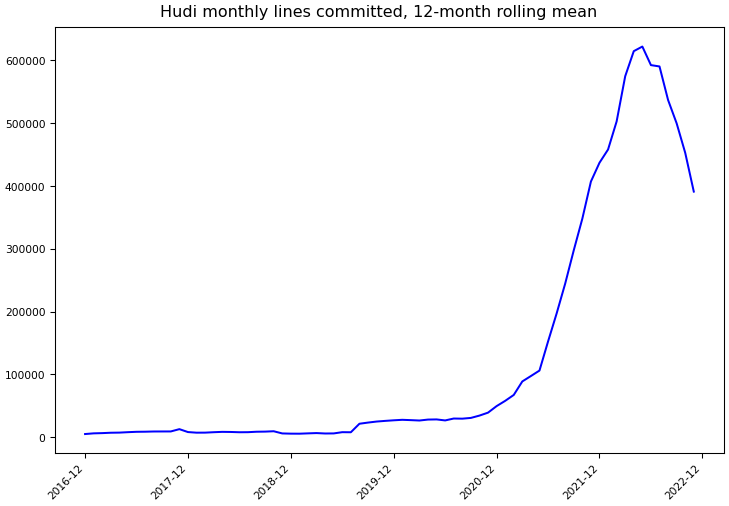
Git Commit Statistics¶
Statistics computed using Git data through November 30, 2022.
Statistic |
Lifetime |
Last 12 Months |
|---|---|---|
Commits |
39,710 |
19,964 |
Lines committed |
10,583,779 |
4,691,434 |
Unique committers |
415 |
195 |
Core committers |
27 |
21 |
Similar Projects¶
Project |
Size Score |
Trend Score |
Byline |
|---|---|---|---|
9.0 |
8.25 |
Apache Beam is a unified model for defining both batch and streaming data-parallel processing pipelines, as well as a set of language-specific SDKs for constructing pipelines and Runners for executing them on distributed processing backends, including Apache Flink, Apache Spark, Google Cloud Dataflow and Hazelcast Jet. |
|
9.25 |
7.0 |
Apache Flink is an open source stream processing framework with powerful stream- and batch-processing capabilities. |
|
8.5 |
5.0 |
Apache NiFi supports highly configurable directed graphs of data routing, transformation, and system mediation logic. |
|
6.5 |
3.0 |
Storm is a distributed realtime computation system. |