Spark¶
The most popular big data processing tool and the successor to Hadoop Map-Reduce. It is mostly used for ETL (extract transform load), but also includes facilities for streaming aggregations, graph computations, and machine learning.
Logo |

|
|---|---|
Website |
|
Repository |
|
Byline |
A unified analytics engine for large-scale data processing. |
License |
Apache 2.0 |
Project age |
12 years 8 months |
Backers |
Apache (Governed by), DataBricks (Commercial Product By) |
Lastest News (2021-10-13) |
3.2.0 We are happy to announce the availability of Spark 3.2.0! Visit the release notes to read about the new features, or download the … more |
Size score (1 to 10, higher is better) |
9.25 |
Trend score (1 to 10, higher is better) |
4.5 |
Education Resources¶
URL |
Resource Type |
Description |
|---|---|---|
Documentation |
Official project documentation. |
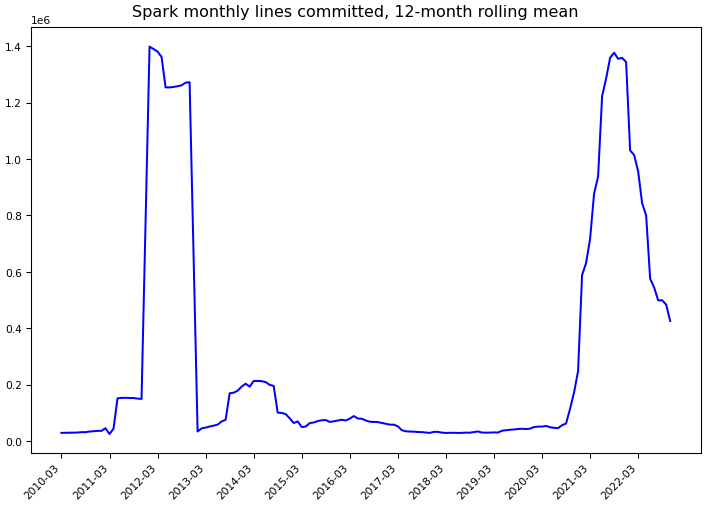
Git Commit Statistics¶
Statistics computed using Git data through November 30, 2022.
Statistic |
Lifetime |
Last 12 Months |
|---|---|---|
Commits |
108,271 |
24,253 |
Lines committed |
47,197,033 |
5,113,840 |
Unique committers |
2,735 |
307 |
Core committers |
14 |
21 |
Similar Projects¶
Project |
Size Score |
Trend Score |
Byline |
|---|---|---|---|
6.75 |
4.75 |
Parallel computing with task scheduling. |
|
6.0 |
6.25 |
HPCC Systems (High Performance Computing Cluster) is an open source, massive parallel-processing computing platform for big data processing and analytics. |
|
9.0 |
8.25 |
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. |
|
6.75 |
4.5 |
Mars is a tensor-based unified framework for large-scale data computation which scales Numpy, Pandas and Scikit-learn. |
|
9.0 |
8.75 |
An open source framework that provides a simple, universal API for building distributed applications. Ray is packaged with RLlib, a scalable reinforcement learning library, and Tune, a scalable hyperparameter tuning library. |