Ingestion¶
Description |
Data ingestion frameworks preprocess incoming data for insertion into a data warehouse or data lake. These operate on data in batches, in “micro” batches, or on streams of records/events. There is some overlap between this ccategory and Workflow Management. Workflow Management projects tend to focus more on the control flow of a pipeline rathe than on the actual data manipulation. |
|---|---|
Projects |
5 |
Lines Committed vs. Age Chart (click to view) |
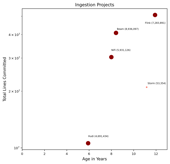
|
Projects¶
Project |
Size Score |
Trend Score |
Byline |
|---|---|---|---|
9.0 |
8.25 |
Apache Beam is a unified model for defining both batch and streaming data-parallel processing pipelines, as well as a set of language-specific SDKs for constructing pipelines and Runners for executing them on distributed processing backends, including Apache Flink, Apache Spark, Google Cloud Dataflow and Hazelcast Jet. |
|
9.25 |
7.0 |
Apache Flink is an open source stream processing framework with powerful stream- and batch-processing capabilities. |
|
6.75 |
8.0 |
Hudi is a rich platform to build streaming data lakes with incremental data pipelines on a self-managing database layer, while being optimized for lake engines and regular batch processing. |
|
8.5 |
5.0 |
Apache NiFi supports highly configurable directed graphs of data routing, transformation, and system mediation logic. |
|
6.5 |
3.0 |
Storm is a distributed realtime computation system. |