Hadoop¶
This project includes key pieces used by the big data ecosystem, such as HDFS and the Yarn scheduler. It also contains the famous Hadoop MapReduce which started the Big Data era.
Logo |

|
|---|---|
Website |
|
Repository |
|
Byline |
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. |
License |
Apache 2.0 |
Project age |
13 years 6 months |
Backers |
Apache (Governed by), Yahoo (Creator) |
Size score (1 to 10, higher is better) |
9.0 |
Trend score (1 to 10, higher is better) |
8.25 |
Education Resources¶
URL |
Resource Type |
Description |
|---|---|---|
Documentation |
Official project documentation. |
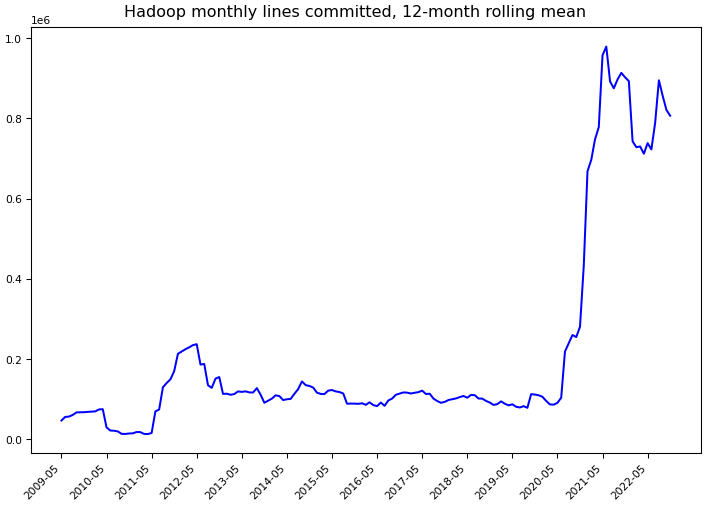
Git Commit Statistics¶
Statistics computed using Git data through November 30, 2022.
Statistic |
Lifetime |
Last 12 Months |
|---|---|---|
Commits |
78,418 |
11,966 |
Lines committed |
37,379,947 |
9,679,161 |
Unique committers |
734 |
147 |
Core committers |
16 |
8 |
Similar Projects¶
Project |
Size Score |
Trend Score |
Byline |
|---|---|---|---|
6.75 |
4.75 |
Parallel computing with task scheduling. |
|
6.0 |
6.25 |
HPCC Systems (High Performance Computing Cluster) is an open source, massive parallel-processing computing platform for big data processing and analytics. |
|
5.0 |
7.5 |
Speed up your Pandas workflows by changing a single line of code |
|
9.0 |
8.75 |
An open source framework that provides a simple, universal API for building distributed applications. Ray is packaged with RLlib, a scalable reinforcement learning library, and Tune, a scalable hyperparameter tuning library. |
|
9.25 |
4.5 |
A unified analytics engine for large-scale data processing. |